
画师:夜予柠檬

1331 字
7 分钟
曲线救国:用Termux+Python脚本实现qBittorrent RSS自动化追番
TIP
起因
事情是这样的:由于四月新番有好几部我都比较感兴趣,但是我平常是在动漫花园一个一个找种子下载的,这样太麻烦了;于是我搜了一下发现 qBitTorrent 有 RSS 订阅功能,但是不知道为什么,在我的网络环境下使用代理时,总是无法正常下载,各种设置都调了之后还是处于一个基本不可用的状态,所以索性就让 ChatGPT 帮我写了个脚本来使用代理抓取种子再传入 qBittorrent 进行下载。
环境搭建
省流:环境就是我手机上的 Termux
由于我正好有一部闲置的手机,所以我就给它装了个 Termux,然后找根线连到电脑上供电。这样这个手机就相当于一个非常小型的 NAS 了(毕竟它的机身存储只有256G)。

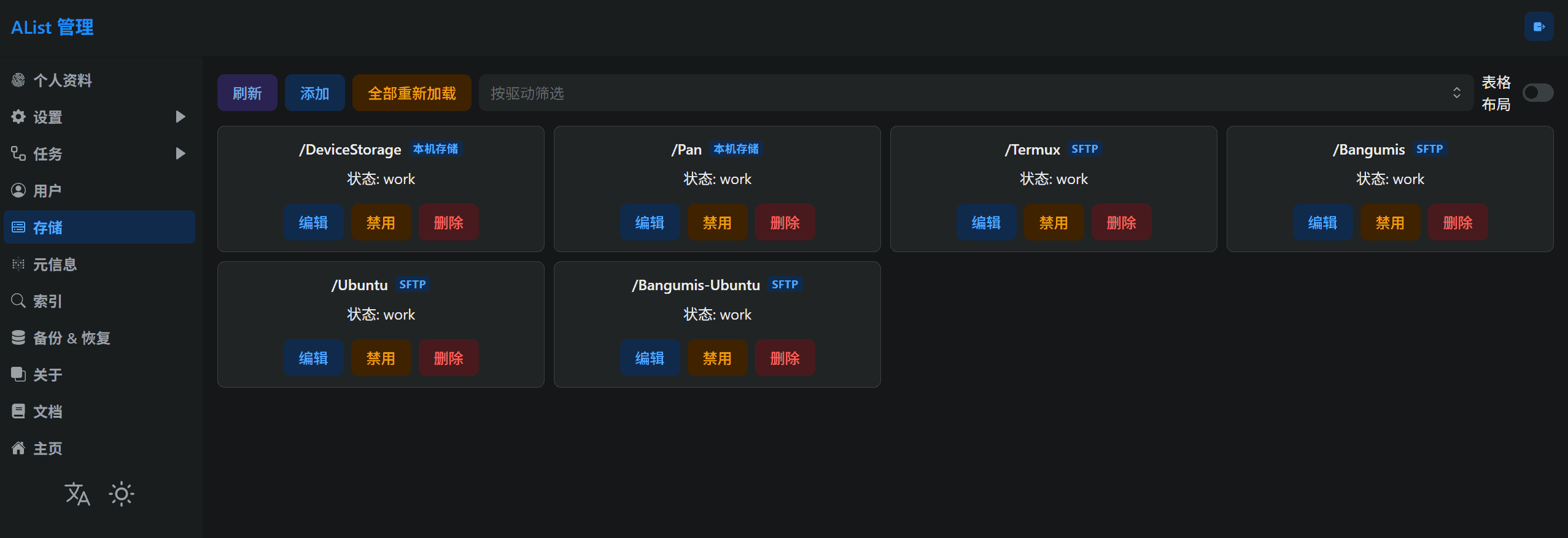
还有一个前提条件,由于我之前在这个手机上装了一个 Alist,所以我可以很方便地用电脑通过局域网访问到这个手机的存储:
正如我在前边的起因里写的那样,由于 qB 在我的网络环境下有点水土不服(电脑端的 qBittorrent 和 我在Termux 里装的 qBittorrent-nox 都是这样),所以只好用脚本去抓取 torrent 再传到 qBittorrent 里了。
脚本内容
省流:下边的两段代码都是 ChatGPT 写的,在主函数里调用的时候修改一下配置参数就可以了
下载器模块:
import requestsimport osimport xml.etree.ElementTree as ETimport ioimport re
# 获取番剧名、字幕组、集数等信息的模块def extract_group(title: str) -> str: match = re.match(r'^[\[\【]([^\]\】]+)[\]\】]', title) return match.group(1).strip() if match else None
def extract_episode(title: str) -> str: patterns = [ r'\s*[-\s_]+(\d{2,3})(?:\D|$)', # e.g. " - 01 " or "_12" or "-099" r'第\s*(\d+)\s*[话集]', # e.g. "第 3 集" or "第12话" r'\[(\d{2,3})\]', # e.g. "[01]" ] for pattern in patterns: match = re.search(pattern, title) if match: return match.group(1).zfill(2) return None
def extract_title(title: str) -> dict: # 1. 移除字幕组 title = re.sub(r'^[\[\【][^\]\】]+[\]\】]\s*', '', title)
# 2. 移除 ★...★ title = re.sub(r'★.*?★', '', title)
# 3. 移除末尾或标题中的 “无修版”、UNCENSORED 等附加信息 title = re.sub(r'[\(\(][^()\(\)]{0,20}无修版[^()\(\)]{0,20}[\)\)]', '', title, flags=re.IGNORECASE) title = re.sub(r'[\(\(][^()\(\)]{0,30}uncensored[^()\(\)]{0,30}[\)\)]', '', title, flags=re.IGNORECASE)
# 4. 匹配 [多语言标题] multi_title_match = re.search(r'[\[\【]([^\[\]【】]+?/[^\[\]【】]+)[\]\】]', title)
if multi_title_match: raw_titles = multi_title_match.group(1) parts = [part.strip() for part in re.split(r'[//]', raw_titles)] else: clean_title = re.split(r'\[\d{2,3}\]|\[\s*(1080p|720p|HEVC|x264)', title)[0] clean_title = re.split(r'[-\s_]+(\d{2,3})', clean_title)[0] parts = [part.strip() for part in re.split(r'[//]', clean_title) if part.strip()]
# 最后移除左右中/英文括号 cleaned_parts = [re.sub(r'^[\[\【\((]*|[\]\】\))]*$', '', p) for p in parts]
return { "main": cleaned_parts[0] if cleaned_parts else None, "aliases": cleaned_parts }
def parse_rss_title(title: str) -> dict: title_info = extract_title(title) return { 'anime': title_info["main"], 'aliases': title_info["aliases"], 'episode': extract_episode(title), 'group': extract_group(title), 'original_title': title }
# 下载器模块def download_from_rss(rss_url, proxy, qb_url, qb_user, qb_pass, base_download_path, autoTMM=False): """ 从 RSS 订阅中获取种子信息并添加到 qBittorrent 中 :param rss_url: RSS URL :param proxy: 代理设置 :param qb_url: qBittorrent Web UI 地址 :param qb_user: qBittorrent 用户名 :param qb_pass: qBittorrent 密码 :param base_download_path: 下载文件夹路径 :param autoTMM: 是否启用自动分类(默认为 False) """ proxies = { 'http': proxy, 'https': proxy } if proxy else None
# 创建会话 session = requests.Session() login = session.post(f'{qb_url}/api/v2/auth/login', data={ 'username': qb_user, 'password': qb_pass }) if login.text != 'Ok.': print('❌ 登录失败') return
try: # 使用请求抓取 RSS resp = session.get(rss_url, proxies=proxies) tree = ET.parse(io.BytesIO(resp.content)) root = tree.getroot()
# 处理命名空间 ns = {'mikan': 'https://mikanani.kas.pub/0.1/'}
# 遍历 RSS 条目 for entry in root.findall('./channel/item'): title = entry.findtext('title') enclosure = entry.find('enclosure') torrent_url = enclosure.attrib['url']
parsed_title = parse_rss_title(title)
# 直接拼接 folder_name,例如 "番剧名 [字幕组]" anime = parsed_title.get("anime") group = parsed_title.get("group") folder_name = f"{anime} [{group}]" if anime and group else None
''' # 根据标题生成文件夹名 title_parts = title.split('[') anime_name = title_parts[0].strip() group = title_parts[1].replace(']', '').strip() if len(title_parts) > 1 else 'UnknownGroup' folder_name = f"{anime_name} [{group}]" '''
print(folder_name) download_path = os.path.join(base_download_path, folder_name)
# 如果文件夹不存在则创建 if not os.path.exists(download_path): os.makedirs(download_path)
# 获取种子文件并上传到 qBittorrent torrent_resp = session.get(torrent_url, proxies=proxies, allow_redirects=True) if torrent_resp.status_code != 200 or b'<!DOCTYPE html' in torrent_resp.content[:100]: print(f"⚠️ 无法下载种子: {torrent_url}") continue
torrent_data = torrent_resp.content files = { 'torrents': ('file.torrent', torrent_data, 'application/x-bittorrent') } data = { 'savepath': download_path, 'autoTMM': str(autoTMM).lower() # "false"/"true" }
add_resp = session.post(f'{qb_url}/api/v2/torrents/add', files=files, data=data) if add_resp.status_code == 200: print(f"✅ 成功添加任务: {folder_name}") else: print(f"❌ 上传失败: {add_resp.text}")
except Exception as e: print(f"❌ 错误: {e}")主函数:
import timefrom apscheduler.schedulers.background import BackgroundSchedulerimport pytzfrom qb_downloader import download_from_rssfrom datetime import datetime
# 配置参数rss_url = 'https://mikanani.kas.pub/RSS/MyBangumi?token=yourtoken'proxy = 'socks5h://127.0.0.1:10808' # 如果没有代理,可设为 Noneqb_url = 'http://127.0.0.1:8080' # qBittorrent Web UI 地址qb_user = 'admin' # qBittorrent 用户名qb_pass = 'password' # qBittorrent 密码base_download_path = '/data/data/com.termux/files/home/Downloads/' # 你的下载目录
# 创建调度器scheduler = BackgroundScheduler(timezone=pytz.timezone('Asia/Shanghai'))
# 定义RSS更新函数def update_rss_data(): try: # 调用下载函数来从 RSS 更新下载内容 download_from_rss(rss_url, proxy, qb_url, qb_user, qb_pass, base_download_path) print(f"RSS更新成功: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") except Exception as e: print(f"RSS更新失败: {e}")
# 设置半小时更新一次scheduler.add_job(func=update_rss_data, trigger='interval', minutes=30)
# 启动调度器scheduler.start()
# 主逻辑if __name__ == "__main__": try: # 调用一次立即下载任务,首次启动时同步更新 update_rss_data()
# 保持程序运行,定时任务会在后台执行 while True: time.sleep(1)
except (KeyboardInterrupt, SystemExit): # 退出时停止调度器 scheduler.shutdown()效果
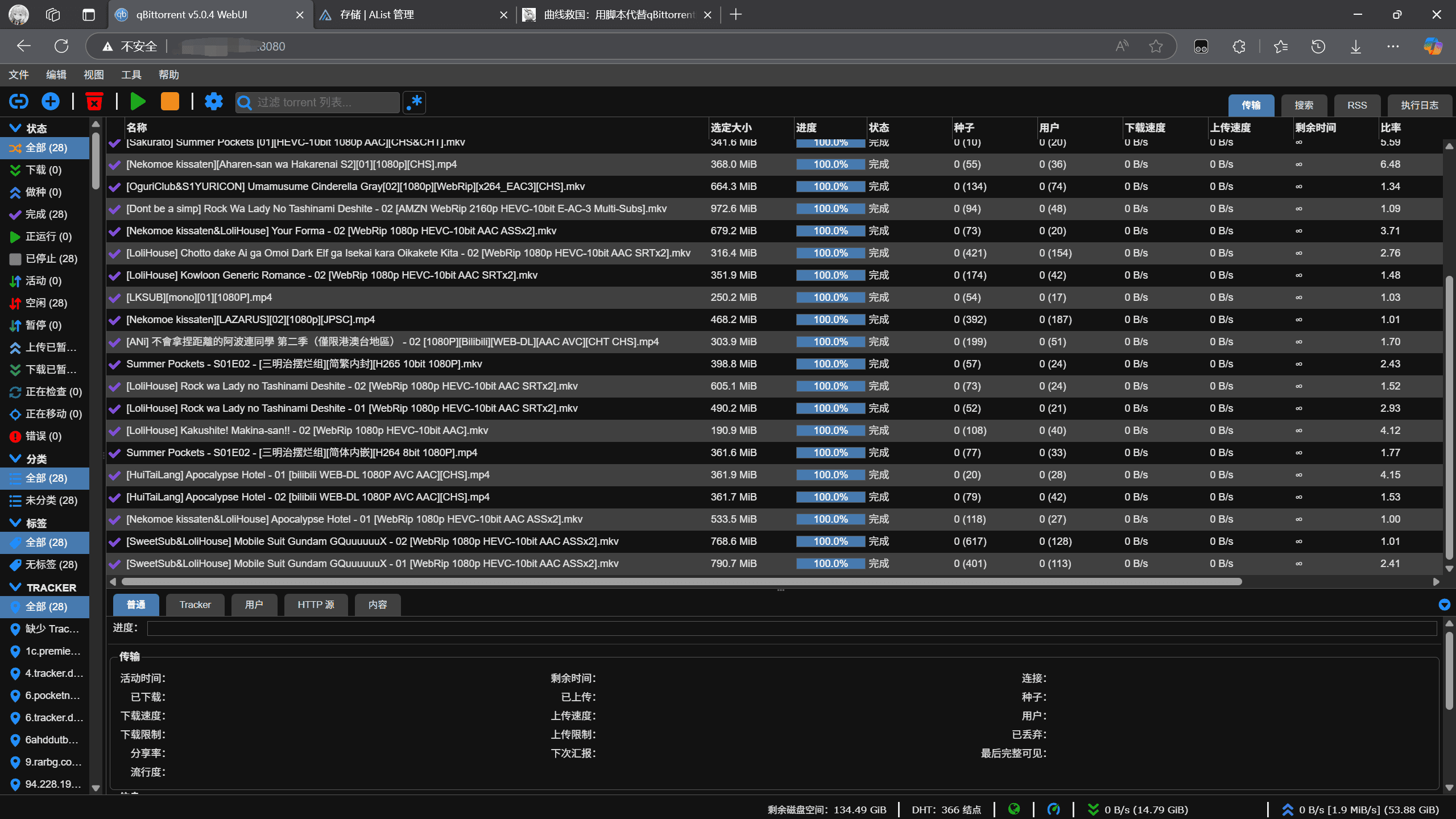
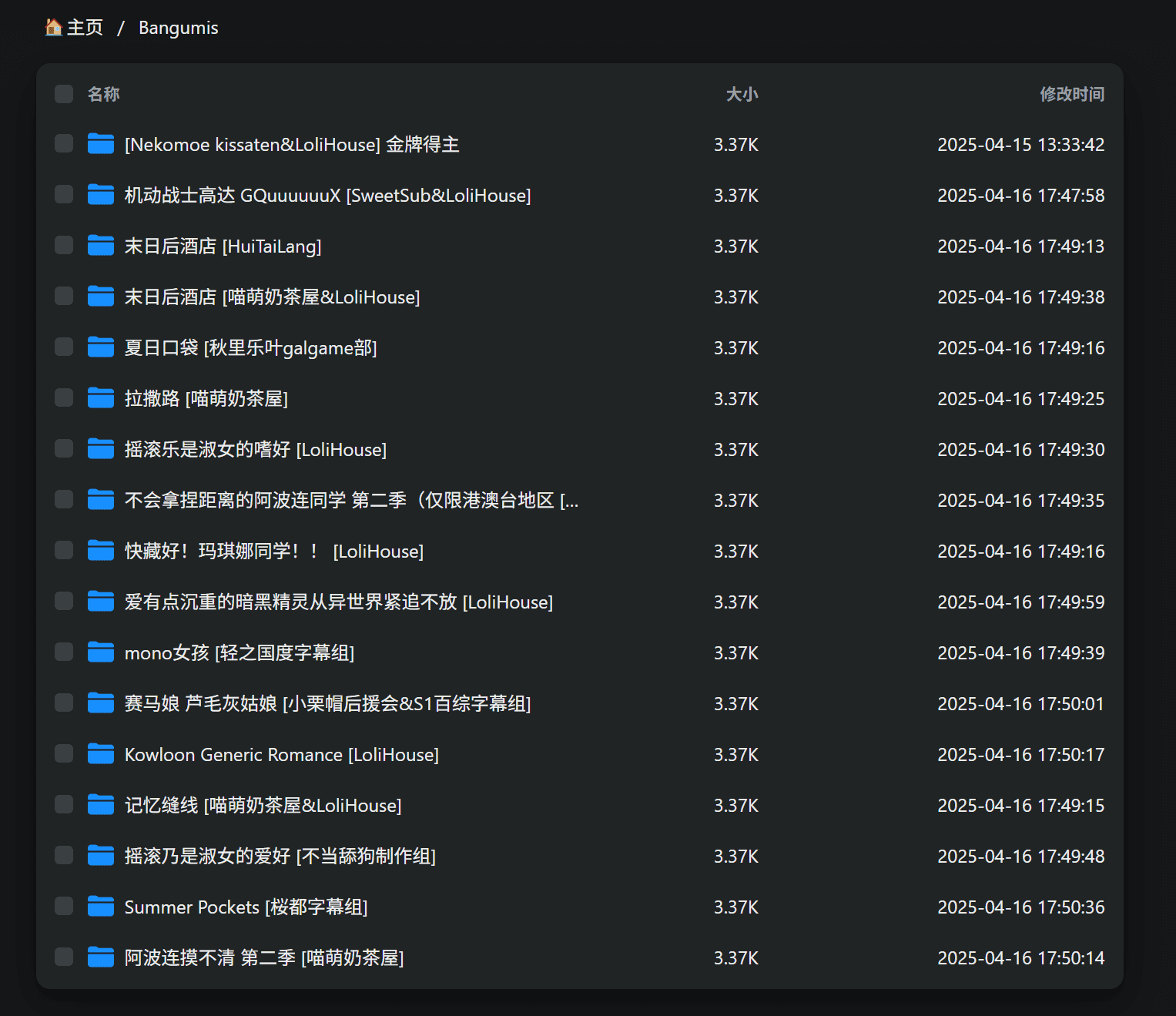
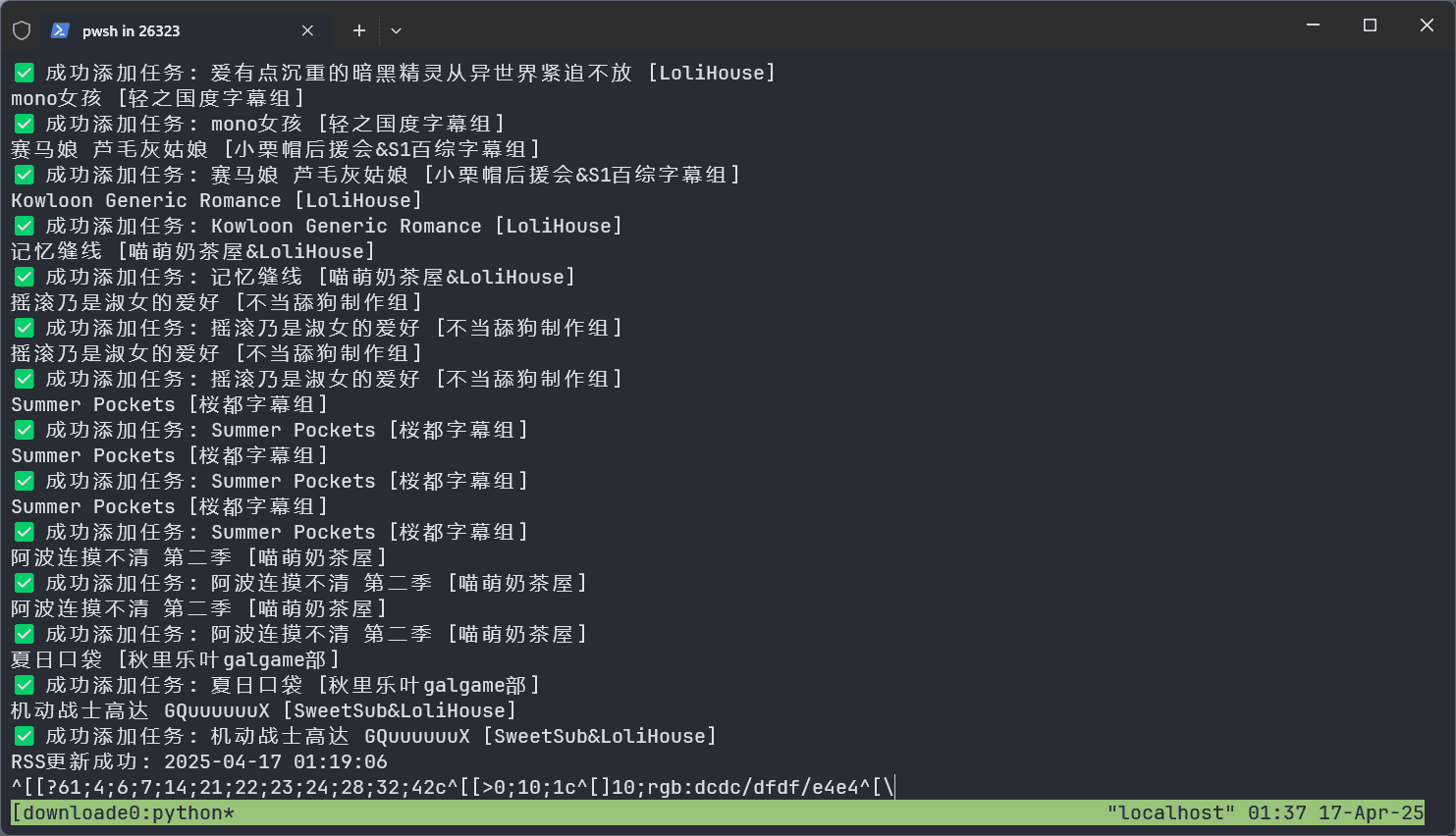
可以自动解析RSS订阅,每半个小时自动更新并且自动下载种子到qBittorrent中,并自动分类进行下载,自动分的文件夹名的格式是“番剧名 [字幕组]”。
曲线救国:用Termux+Python脚本实现qBittorrent RSS自动化追番
https://blog.rimrose.work/posts/rss_bangumi_download/